本文主要总结了C++在原子操作上的内存模型以及内存排序标准。
相对来说,C++已经是比较接近系统底层的语言了,C++设计也是希望如此,毕竟它本身已经如此复杂了。在C++ 11的标准里,推出了非常多的新特性,它们让C++变得非常灵活,而它们都依赖于标准里的多线程内存模型。但可能大部分的开发者都不知道这些,因为一般情况下,他们只需要通过mutex这一类高级的同步锁,来在多线程下解决数据竞争问题。至于这些锁是如何实现的,对他们来说并不重要。但是如果要接触到更底层的原理,或需要编写lock-free数据结构,亦或者是需要做更高性能的优化时,那么我们就需要理解这些更接近「机器语言」的数据结构和设计。有时候,一些原子类型或者原子操作,甚至可以让代码缩减到只有1-2个CPU指令。
为什么会有这篇文章
objc-block的源码中,有一段C++实现的 objc-block-trampolines.mm 部分,其中有一个lock-free的设计。
首先什么是
lock-free?
字面意思,lock-free就是无锁,简单的解释就是:一个系统设计,在没有阻塞,没有锁的情况下,实现多线程之间的数据同步。
接下来直接看下这段剔除了无关代码之后的核心部分
1 | // fixme C++ compilers don't implemement memory_order_consume efficiently. |
代码实现了一个无锁的单例,单例对象为trampolines。其中get()和Initialize()函数是可以多线程并发执行的。
首先get()无需解释,直接返回当前的单例对象。如果只有读操作,那在多线程环境下本身也没什么问题。(PS:这种设计下,单例是有可能返回空的)
接着看Initialize(),它的本质其实是一个双判初始化操作,其中if (get()) return;是第一次判断,第二次判断就是trampolines.compare_exchange_strong(old, t, memory_order_release):
它将trampolines变量和old变量相比较,如果相等,那么就让t「替换」掉trampolines。
这句代码等价于
1 | if (trampolines == null) { |
唯一不同的是,前者是一个原子操作。也就是说,虽然Initialize()函数可以有多线程并发执行,但是compare_exchange_strong()函数同时只有一个CPU可以执行,并且这个操作是不能被中断的。
假设当前有两个线程在同时执行,在第一个线程将trampolines通过compare_exchange_strong()赋值后,第二个线程compare_exchange_strong()判断一定会返回false,这也就是为什么返回false,需要释放已创建的t。
一切都可以合理解释,但是其中的第三个参数memory_order_release和MEMORY_ORDER_CONSUME(memory_order_relaxed)是用来做什么的?
前序
谈谈指令乱序
在学校从导论中就已经了解到,现代CPU早已经进入了多核时代,现代的编程技术,也早已支持并发编程。分支预测,乱序执行,指令优化,都会让最终运行在机器上的代码,不再是我们编写代码的时候所预期的那样。
除了这些以外,各类编译器还会根据自己的实现和规则,对编译的目标代码进行优化,指令重排就是这些优化中重要的一项,但指令重排对这些代码的开发者来说完全黑盒。
下面用一段简单的代码来举个例子:
1 | int A = 0; |
Clang编译上面这段代码后会产出如下的汇编:
可以很明显看到,先比较了B == 0,后加载了 A = 1;😱
我们把我们看到的理解代码的顺序,暂且叫代码顺序,而这种不按照代码顺序来执行的编译器行为称之为指令乱序。从编译器的角度来看,它只需要保证在单线程的情况下,代码能够正确地执行,并且符合单线程的预期即可。就上面的代码而言,「看起来」和「执行结果」的确是没有问题的。但是在多线程环境下,这个结论就不再成立了。因为编译器是不知道多线程环境下代码执行的先后顺序,也不知道哪些变量会在线程之间共享,这个时候指令乱序会导致严重的后果。了解一下关于「锁」的反面例子:
「锁」是绝大部分开发者在编程的时候,会选择用来解决多线程下的数据竞争问题。不论是mutex,还是自旋锁,用锁来保护临界区,是一个程序员的基本操作。那么按照上面编译器不可预知的指令乱序行为,如果「锁住」的临界区内的代码,在被编译优化后,理论上不会跑出临界区吗?比如我们把上面的代码稍微改一下。
1 | int A = 0; |
A = 1会不会跑出来??
线上暂无故障,我们肯定可以理直气壮地说,这个代码100%不会有问题的,那为什么呢???
内存可见性
除了指令乱序,还有一个问题会影响代码的一致性,那就是内存可见性。我们知道,CPU执行指令的速度,和内存的读写速度不是一个量级的,因此CPU引入了多级缓存,就像下面这样(原谅我的画功):
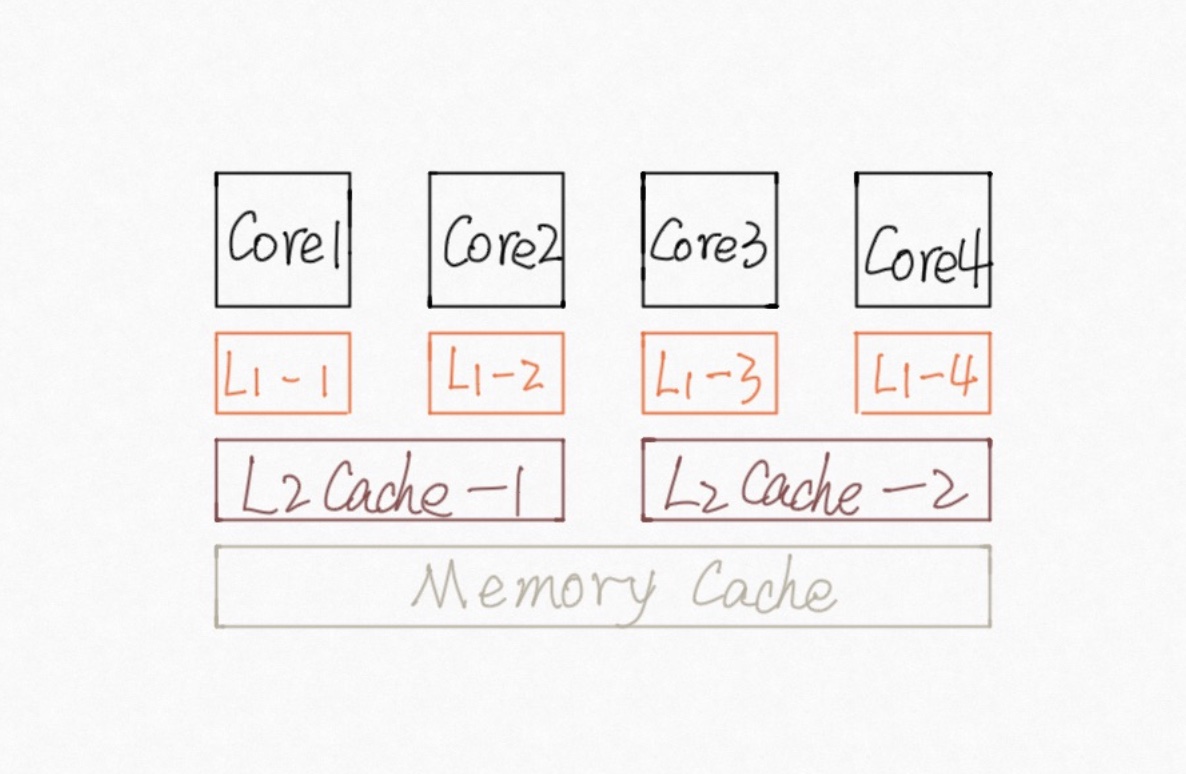
每个内核都有自己的L1,L2甚至L3缓存,为了提升运行速度,在内核读某个内存值的时候,如果在缓存内命中,那么很有可能就会直接使用缓存内的值;同样的,写入操作也有可能只会临时写入缓存;当触发缺页,或者某个回写机制的时候,这些缓存中的值才会真正刷新到主存中去。从这张图垂直得来看,其实每一个内核都有自己独立的缓存,而各个缓存之间的同步机制,会影响内存的「可见性」。
举个例子
1 |
|
上面这个例子, 在多核CPU上执行最终结果大概率是小于2000的。当一个内核(线程)在读取变量之后,另一个内核(线程)对它做了修改,但没有回写主存,也没有同步到其他内核(线程)中去的时候,就会出现不一致的情况。这块内存对于不同的线程的可见性也就不一致了。
原子操作
原子操作,就是在单核CPU上,一个CPU指令就能完成的操作,比如MOV,INC等等。如果一个操作需要多个指令来完成,那么在多个指令之间,有可能会触发系统中断,在中断过程中,修改了这个操作的中间变量,这个操作就不再「原子」。
C++提供了std::atomic来实现原子操作, 还是上面那个例子,稍微改一下:
1 |
|
这里的++v等价于 v.fetch_add(1),它可以保证任意一个线程对v的修改,对其他线程是立刻可见的。保证了任意一个线程每次读到的v一定是当前的最新值。
内存排序
原子变量和原子操作其实已经解决了内存可见性问题,内存排序就是用来解决乱序问题。
概念
网文有很多在解释内存排序,都会提到这些概念,他们都来自C++并发编程的标准文档中。在解释模型之前,确实需要理清这些概念,避免后续解释混淆。
先整体解释一下
std:memory_order
std:memory_order 指定了一个原子操作的周围是如何来排序一些非原子操作的内存访问顺序的。在多核CPU上,某个线程观察到的变量的变化顺序,可能和真正修改这个变量的线程的写入顺序完全不一样,就是因为上面提到的指令乱序,甚至可能在单核CPU系统上依旧会存在相似的问题。标准库给到的默认行为是顺序一致性行为,这种会影响性能。但是除了原子能力,标准库提供了std:memory_order这个参数来指定特定约束。
“Sequence Before”(排序上在…之前)
“Sequence Before”是一种在单个线程内的两个调用(表达式)之间,非对称的,可传递的关系。
- A 排序上在 B 之前 等价于 B 排序上在 A 之后, 前者 A 计算会在 B 计算开始之前结束。
- 如果 A 不是排序上在 B 之前,并且 B 也不是排序上在 A 之前,那么就会有两种可能:
- A B 两次计算是无序的: A B计算可能在任一顺序,并且有多个重叠部分的情况下发生。
- A B 两次计算的顺序是随机的: A B计算可能是在任一顺序,但是没有重叠。如 A 在 B 开始之前结束,或者 B 在 A 开始之前结束。
举个例子
1 | r1 = y.load(std::memory_order_relaxed); // A |
称 A 排序上在 B 之前
“Happens Before”(在…之前发生)
除了”Sequence Before”关系之外,”Happens Before”还包含了”Inter-thread happens-before(线程间,在…之前发生)”的关系
依赖关系
在同一个线程内,A 计算排序上在 B 之前,还会给B附带上一个依赖关系(那就是 B 依赖 A),下面的表述都是 B 依赖 A。
- A 计算的值被用来作为 B 计算的操作数,除了
- B 是 std::kill_dependency
- A 是内置的操作符
&&||?:或者,的左值 - A 向标量对象 M 写入,B 从 M 读取
- A 给另一个计算 X 引入依赖关系,而 X 给 B 又引入依赖关系。(即依赖的传递)
三种内存模型
对原子操作,C++有6种内存序列,分别是:
memory_order_relaxedmemory_order_consumememory_order_acquirememory_order_releasememory_order_acq_relmemory_order_seq_cst
在不指定的情况下,默认是memory_order_seq_cst。
虽然有6种内存序列,但他们只对应了3种模型(其实是4种),分别是:
sequentially consistent(顺序一致性排序) 「memory_order_seq_cst」acquire-release(获取-释放序列)「memory_order_acquire,memory_order_release,memory_order_acq_rel」relaxed(松散序列)「memory_order_relaxed」
第四种consume-release模型因为memory_order_consume序列目前在实现上有性能问题,不建议使用,也就不讨论这个。
顺序一致性的模型
上面提到了,内存排序默认就是memory_order_seq_cst,对应的模型就是「顺序一致性排序模型」。
顺序一致性,意思是在程序执行过程中,所有对于原子类型数据的操作,就像是我们从源码看上去,以我们所看到的那样。
换句话说,顺序一致性,在多线程的环境下,原子类型的数据,将会像在单线程下处理一样 —— 一个操作接一个操作排好顺序来执行。到目前为止,这个顺序是最好理解的,在多线程环境下,每一个线程,对原子数据进行操作的优先级都是一样的。
但是这也就意味着,多线程下对于这个原子的操作是无法被排序的,也就是说CPU是无法针对这些原子操作的前后进行编译优化的。
非顺序一致性的模型
非顺序一致性的模型,包含两种,一种是「松散序列」,另一种是「获取-释放序列」。
在这种模型下,就不再和上面一样有一个「全局有序的事件队列」了,细想一下这个模型在多线程下就会变得非常复杂了。在理解这种模型的时候,我们必须要抛开我们固有的多线程操作的心理预期模型,原子操作在不同线程中看到的将会是不同的样子。
松散序列
松散序列是非顺序一致性模型中的一种,简单的来说,因为指令乱序的存在,使用「memory_order_relaxed」这一种模型,会让这个原子操作,「可能」出现在这个原子操作序列的任一阶段。换句话说,它只会保证操作的原子性与修改顺序的一致性(它只起到了原子操作的作用)。
举一个例子来理解
1 | std::automic<int> x = 0; |
线程1 的操作为 A -> B, 线程B的操作为 C -> D, 所以如果按照顺序一致性的模型来理解的话,那么就会有下面的几种可能性
- A -> B -> C -> D
- A -> C -> B -> D
- A -> C -> D -> B
- C -> D -> A -> B
- C -> A -> D -> B
- C -> A -> B -> D
这6种可能性执行完之后,r1=r2=0, 或 r1 = 42,r2 = 0;
但是在松散序列下就不一样了,线程2中,y原子操作并不依赖任何操作,所以编译器可以选择将 D 操作顺序移动到 C 操作之前。
所以,在上面的6种可能性中,C,D可以交换,产生12种可能性。结果中可能会产生 r1=42,r2=42 这种情况。
再举个例子,这个例子来自「C++ Concurrency In Action」
1 |
|
x, y在同一个线程内「依次」原子写入 true。另一个线程内,在y写入true之后,判断x是否已经是true了,如果是则z++。
从顺序一致性的模型来理解的话,断言是肯定不会触发的,因为在y变为true的时候,x一定已经是true了。
但是同样的,在松散序列下,x,y 没有任何相互依赖关系。A,B操作是有可能会指令乱序的。所以在这个情况下,断言是有可能触发的。
「memory_order_relaxed」这个模式最典型的运用就是shared_ptr引用计数中的计数+1部分
1 |
|
因为fetch_add可以保证操作的原子性和修改内存的一致性,所以计数不会出错,而目的也只需要保证最终计数的准确性,这里使用memory_order_relaxed就可以达成目的。
获取-释放序列
上面两个序列是两个极端,一种是非常严格的策略,另一种则是非常宽松,而获取-释放序列则是位于两者之间。
| memory_order | description |
|---|---|
| memory_order_release | 仅用于 store 操作,当前线程内在 store 操作之后的任何内存读写操作都无法被重排到store操作之前 |
| memory_order_acquire | 仅用于 load 操作,当前线程内在 load 操作之后的任何内存读写操作都无法被重排到load操作之后 |
当线程A中的原子变量的store操作被标记为memory_order_release,而线程B中同一个原子变量的load操作被标记为memory_order_acquire属性的时候,在A线程中store操作之前发生的所有(非原子的和relax的)操作,都会在B线程load操作之后全部可见。也就是说,需也仅需load操作完成,那么B线程内可以看到A线程之前的所有写入操作。
这种同步关系,只会建立在不同线程对于同一个原子变量的release和acquire操作之间,其他线程看到的顺序就不可预知了。
一些互斥锁,例如std::mutex或者自旋锁,就是release-acquire内存同步的一个典型案例: 在线程Arelease之前,临界区内发生的所有事情,都必须在Bacquire进入临界区后可见。
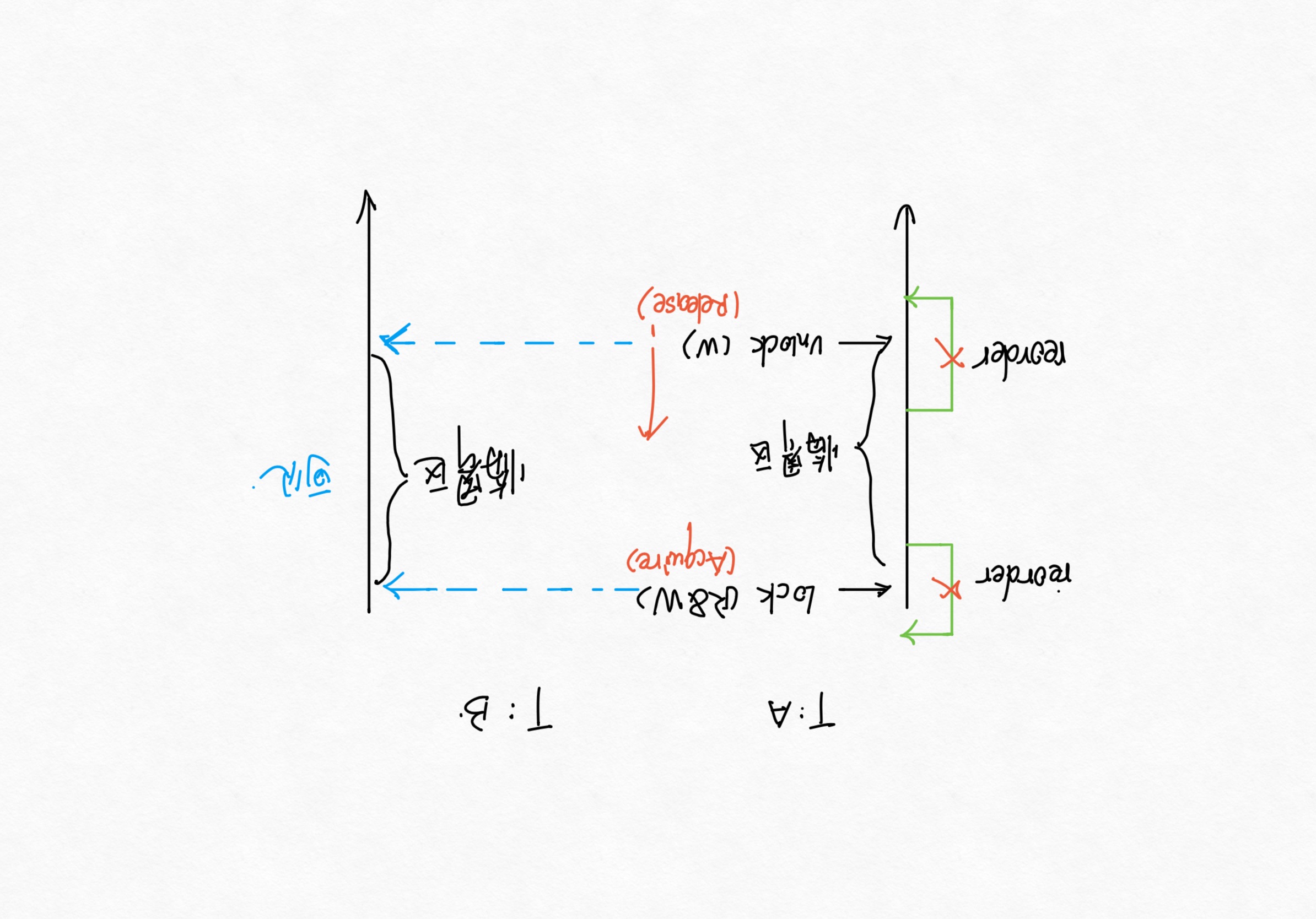
上图完整的解释了锁内临界区内的代码,是不可以被重排到临界区外的。
再来看一个引用计数的减一例子:
1 | control_block_ptr->Write(); |
引用计数减一的时候这里用的是acq_rel, 而不再是relax了。因为这里涉及到了数据的销毁,看下如果依旧使用relax会发生什么。

对象的读写可能会被重排到 fetch_sub 之后,而此刻如果另一个线程同时也正在销毁对象的时候,发现fetch_sub已经是0了,随后就将数据销毁了。从线程B单个视角来看的话,销毁发生在对象写入之后,不会有异常产生。但是线程A和B同时执行的时候,A线程的写入操作,就有可能会发生在线程B的销毁之后了。
如果这里对fetch_sub指定为release排序模型,禁止对象写入重排到原子操作后面。
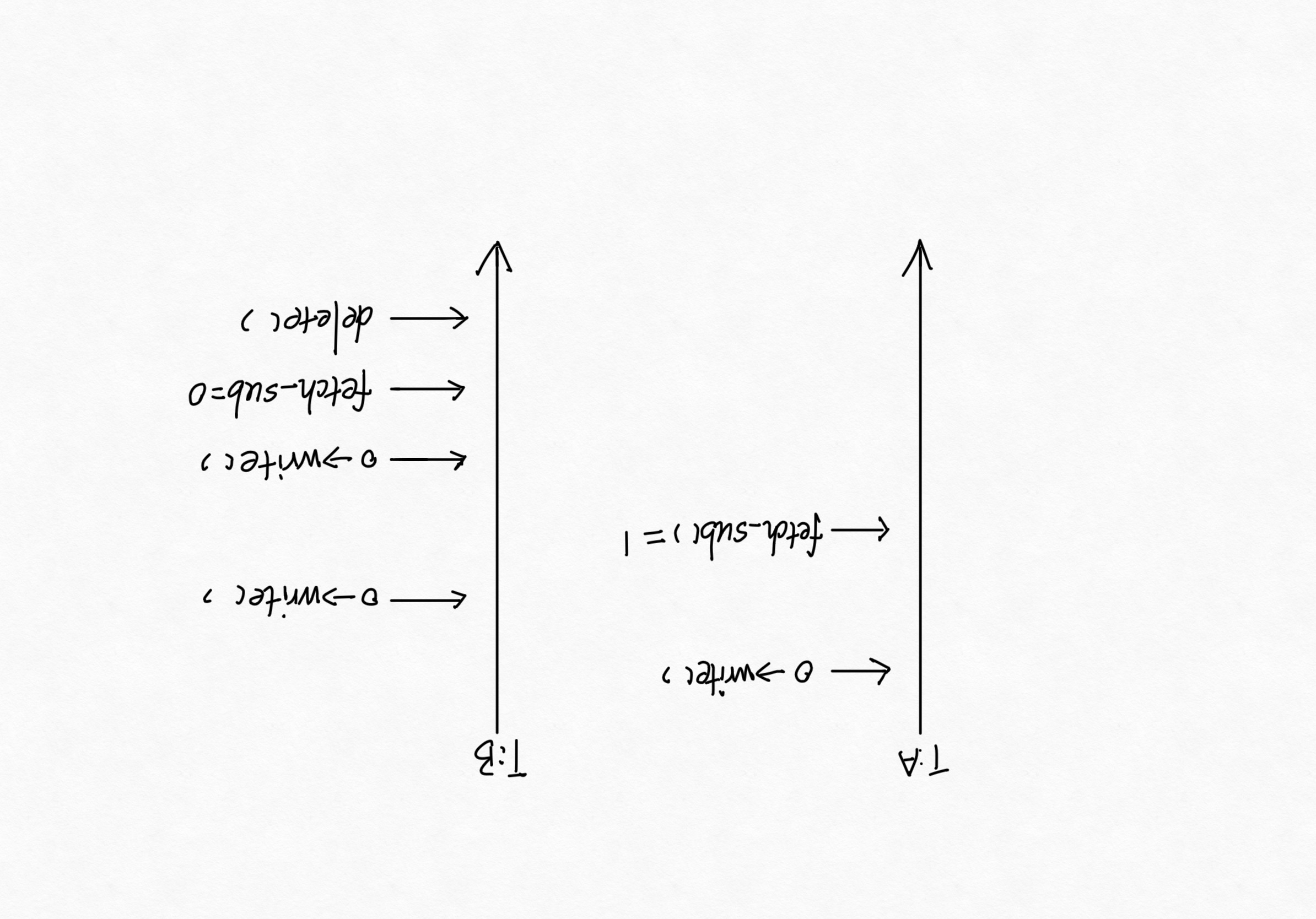
这样一来,因为对象的写入操作永远保证在fetch_sub之前,那么delete操作之后也就不可能会出现对象写入操作(这里是指在引用计数的环境之下)。
同样的原理需要考虑对象操作在fetch_sub之后,这时候就需要acquire操作。同时需要acquire和release,即memory_order_acq_rel。
解释开始的问题
为什么锁内临界区的代码不会被重排序到临界区之外?
这个问题已经解释过了,release-acquire模型可以保证临界区的数据竞争问题。
回头再来分析最开始的
lock-free的代码
代码中使用了memory_order_consume 这个属性,这个属性在上面分析的时候跳过了。一句话概括,它在cppreference中定义和memory_order_acquire相似,只是将”当前线程内在 load 操作之后的任何内存读写操作都无法被重排到load操作之后”这个定义内的”任何内存读写操作”, 变更为”依赖当前原子变量的读写操作”。
是不是很眼熟?和mutex的设计如出一辙,只是它不再像mutex一样会阻塞线程。
从mutex的设计角度思考,Initialize()函数内get()和compare_exchange_strong()之间的代码就是”临界区”,临界区的核心代码就是将trampolines修改为t。
但是因为实现的性能问题,cppreference是不建议使用consume, 苹果的源码里更是用宏将它改为了relax。那这样会发生什么问题?
relax可以让原子变量的访问性能达到最优,但是从临界区的角度来思考,relax就没有任何排序限制了。那么临界区内的代码就有可能会被重排到get()之前,比如说dlopen被重排到最前端,如果一旦后续get() return;,那么造成内存泄漏。
苹果可以确保clang不会这么干,但毕竟C++也只是一个标准,各家编译器的实现大不相同。苹果工程师能做的,只有祈祷🙏🏻cross our fingers。
参考文献
浅析C++ atomic 和 memory ordering
聊一聊原子操作
内存乱序与C++内存模型详解
聊聊内存模型与内存序
C++ 内存模型
lock-free 编程介绍
confusion-about-implementation-error-within-shared-ptr-destructor
memory-order-in-shared-pointer-destructor
cppreference